SNOWFLAKE ARCHITECTURE
Snowflake’s is based on the hybrid architecture of below two traditional architecture
1. shared-disk architectures
2. shared-nothing database architectures
Snowflake is a cloud-based data-warehouse, which is available on all major cloud service provider like AWS, Azure and on Google Cloud. For snowflake fundamental please click on the link to go to our earlier article http://mycloudplace.com/what-is-a-snowflake-data-warehouse/
Snowflake charge users on the per-second basis of computation or query processing. It is a pay as you go service. Snowflake system is designed in a way to scale and perform without any indexing, tuning, partitioning and physical storage design considerations, so we do not have multiple knobs to tune the database performance, we have few knobs to tune the cost to optimize the paper bills. Snowflake’s hybrid architecture has below three layers
- Cloud Services Layer
- Query Processing Layer
- Database Storage Layer
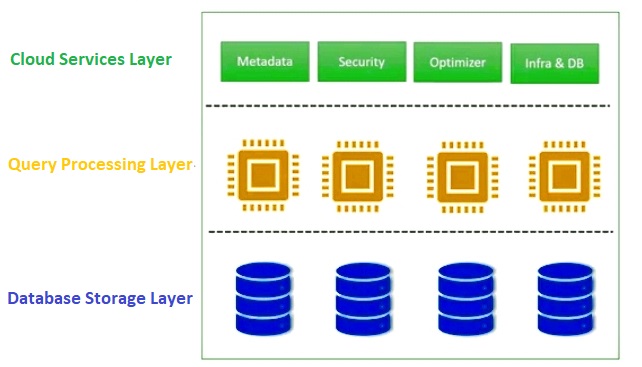
For detail please refer the Snowflake official link
https://docs.snowflake.com/en/user-guide/intro-key-concepts.html
1. Database Storage Layer
Snowflake stores the data in cloud storage. when we load the data in the snowflake, Snowflake internally re-organizes that data into columnar format. It is snowflake responsibility to optimize and compressed the data in it’s internal storage also snowflake manage the file size, structure and it’s meta-data. The data managed by Snowflake are not directly visible nor accessible by users. We can only access the data through SQL query operations run using Snowflake.
Snowflake we will have two things Database and Virtual Data warehouse, the Database is the storage layer, it allows as to define a database, a bunch of schemas and then add tables to the schema. Once we have table we can start loading data into those tables.
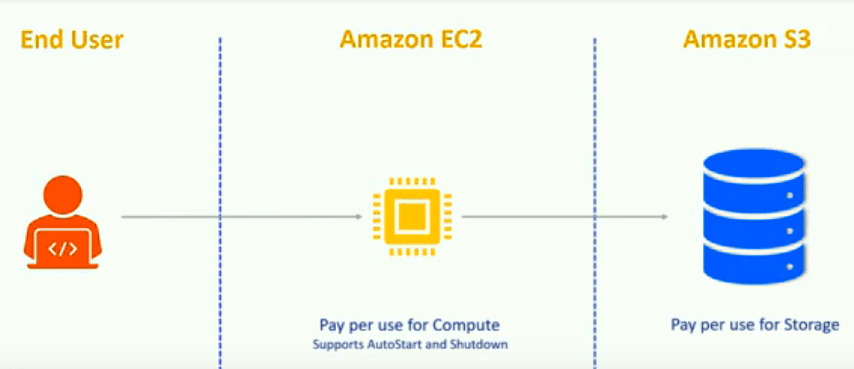
The unique thing about snowflake is the data in the tables are stored in AWS S3 and it consumes storage only cost, there is no compute cost attached to database unless we are executing DDL or DML queries, we will pay for the compute cost while we running DDL statements to create a database, a schema, table or other structural objects, if all these activities take 20mins we will pay for only for that 20 in of computing cost, once our table structure is in place we will load data into the table, if our data load job is run for an hour in a day so will be paying for the compute cost for an hour rest time will pay for storage.
2. Query Processing Layer
It is also called virtual warehouses layer. This is the processing layer. Snowflake processes queries using “virtual warehouses”. Every virtual warehouse is an massive parallel processing (M.P.P.) compute cluster which contain multiple compute nodes. Every virtual warehouse never share compute resources with each other.
We can deeply understand the query processing layer with below points
- This is nothing but compute cluster, they are named after Virtual warehouse, but instead of machines Snowflake termed them as Warehouse. We can create Warehouse of different sizes depending upon our requirement it could be single node or multi node warehouse.
- These nodes are nothing but AWS EC2 instances but they are internal to warehouse and we don’t directly interact with them.
- Creating a warehouse does not have any cost associated with it is just metadata creation, and also we can have more than one warehouse configuration, the point is we create our compute resource definition and start it only when we want some computation and shut it done once it’s done.
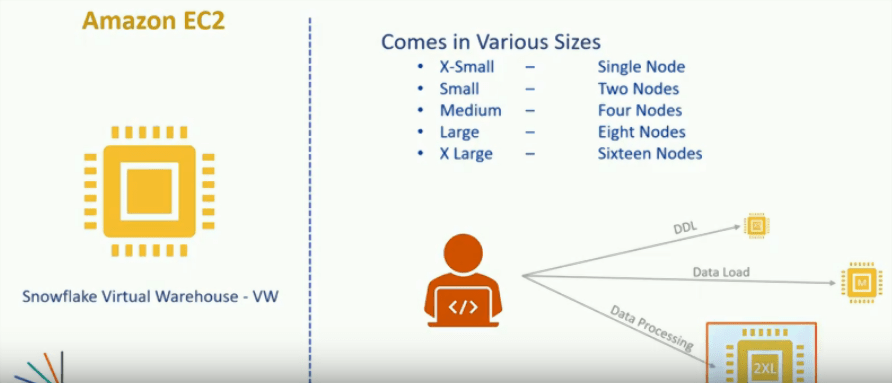
- A job that runs for 5 minutes on a 32 node warehouse and triggers 24 times a day is charging us for 2 hours of a 32 node warehouse, we can use the same warehouse to execute multiple concurrent queries, in that case as the queries are submitted to a warehouse the warehouse allocates resources to each query and begins running them.
- If sufficient resources are not available to execute all the queries additional queries will be queued until the necessary resources become available.
- We have all the flexibility to plan the work load and reuse our warehouses.

- It also offers a unique idea of multi cluster warehouse for auto scaling
- For Example we created a multi cluster warehouse and started a query on the warehouse, snowflake would start our query normally in the same warehouse. However, if we start submitting more and more queries on the same warehouse at some point they will consume all the resource and additional queries will be queued until existing ones are complete, But a multi cluster warehouse will detect this scenario and automatically launch a new warehouse to execute the queued SQLs.
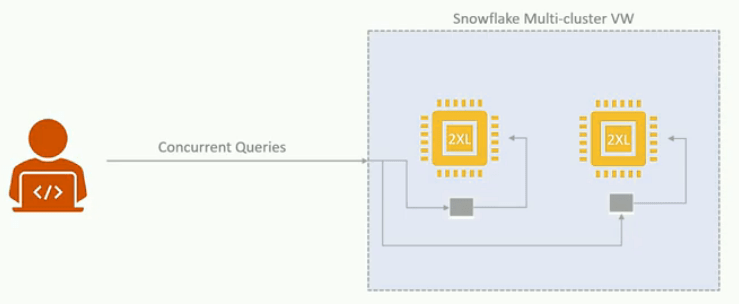
- Snowflake allows us to configure automatic scale up by starting additional warehouse and scale down by shutting down the warehouse depending upon the workload.
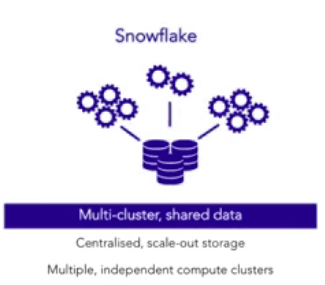
- Snowflake tries to take the best of both shared-disk and shared nothing architecture, it has a single data and which means we don’t have to manage shadow copies and log syncing, and it is a single copy but we then have the ability to run up multiple independent scaled compute clusters and it is called as virtual warehouses, as it is built for a cloud fabric we don’t have to worry about the infrastructure challenges we have to deal with traditional architecture.
- It uses cloud as its storage platform, in fact it uses object storage for example if we are using AWS cloud stack it will store it in S3. For the end users we don’t need to worry about how it is stored, we don’t need to deal with the data stored in with format specifically designed for servicing high performance analytics queries.
- For example if we are using S3, S3 is very big so we can be able to scale our environment, we can start with scale of megabytes and we can grow our environment to the scale of petabytes , even if we have petabytes of data in single table it will still give us excellent amount performance for queries.
- One of the key element of the architecture is that the storage and the computing is done separately in snowflake architecture. As mentioned S3 is the storage element and the computing layers are just clusters of compute nodes, and any data is not stored in this compute nodes, it uses local storage as volatile caching to help accelerate query performance, which means it is able to start and stop these nodes independently of the storage which save cost, we can have multiple compute clusters which is called as virtual warehouses, we can have them working simultaneously over a single copy of the data held centrally.
3. Cloud Services Layer
Snowflake runs on cloud platform so all the major operations perform in this layer. These operation includes
- Infrastructure management
- Authentication
- Metadata management
- Query parsing and optimization
- Access control

What is a Snowflake Data Warehouse?
Pingback: What is a Snowflake Data Warehouse? - Mycloudplace
Very good introduction article 👍 I was looking for one like this.
Very good article, I was for once with sort of introduction. Thank you for sharing
Pls share more on data processing